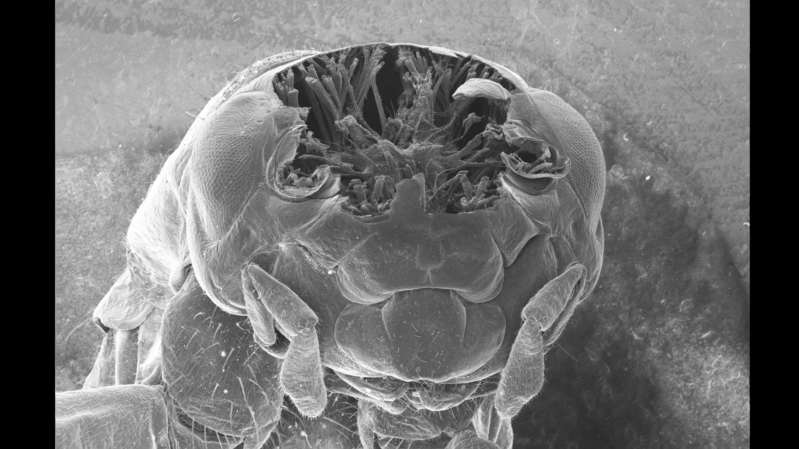
Unlike most cutting lasers, femtosecond lasers don’t vaporize materials; rather, they produce such short, intense bursts of light that the affected region is ablated without having the chance to heat its surroundings. This makes them good at cutting away material without damaging the surroundings, something [Ben Krasnow] exploited to cut cross-sections of samples while still in a scanning-electron microscope.
In this case, the samples were crickets, and before imaging they had to be prepared. First, the bodies were soaked in glutaraldehyde to cross-link the proteins and stabilize the structure. Next, a series of solvent exchanges replaced the water in the bodies with a low-surface-tension solvent; this meant that during the next step, drying, surface tension wouldn’t distort the crickets’ internal structure. Finally, the insect bodies were charred under argon, which made the bodies conductive and more absorptive to laser light.
The laser itself and the scanning galvo are mounted outside the microscope, and shine in through a transparent window. To protect the detector and electron optics from a spray of ablated carbon, a servo motor swings an aluminium shutter between these and the sample while the laser is active. This caused some mysterious problems during testing: after the first ablation run, the electron microscope’s image would contain so much noise as to be unusable, but it would improve over time. As it turned out, the shutter was painted, and the other side of the paint was getting coated with charged carbon particles. This created a small capacitor which disrupted the electron optics as it discharged. Eventually, after solving this and a few other strange problems, [Ben] was able to take several time-lapse videos of the laser gradually ablating a cricket, 30 microns at a time, revealing its inner structure.
We used to worry about fire. A house fire could claim the photo albums, the letters, the dusty box of cassette tapes in the closet. We knew exactly what we were protecting, and from what. The threat was not only visible, but olfactory: you could smell smoke.
Now the threat is something else entirely: not loss through destruction, but loss through indifference. The server shuts down. The startup pivots. The platform “sunsets” a feature you’d spent years filling with memories. And just like that, a decade of your life becomes a page of 404s.
The economics of attention
I’ve been publishing on the web since 1995. I’ve watched links I wrote, links I cherished, slowly turn to dust. Not because the ideas were bad, or the writing was thin, but because someone decided a database was too expensive to maintain, or a domain registration lapsed, or a CMS migration “couldn’t prioritize” backward compatibility.
The fragility isn’t in the medium—it’s in the economics of attention. Digital memory is fragile not because bits decay (though they do), but because someone else owns the shelf.
And it’s not just the web. Think of the photos you’ve “saved” to a cloud service that changed its terms. The videos you uploaded to a platform that no longer exists. The notes you carefully organized in an app that got acquired and shuttered. Each time, you were told you were “backing things up.” You weren’t. You were relocating them—moving your memories from your own bookshelf to a rented storage unit with a demolition clause.
The cruelty of digital loss
There’s a cruelty to the way digital loss sneaks up on you. A flooded basement announces itself. A dead hard drive grinds and whirs in protest. But a cloud account that quietly vanishes? A social graph that’s “replatformed” into oblivion? That’s a disappearance in broad daylight. You don’t even get a funeral. One day you click a link and it’s just… gone. No explanation, no elegy, just a redirect to a marketing page.
The Cloud is not a place
We need to stop pretending that “the cloud” is a place. It’s not a place. It’s a promise—and promises are only as good as the entity making them. The web was supposed to be decentralized, resilient, a network of nodes that could route around damage. But in practice, we’ve spent the last decade centralizing our lives into a handful of walled gardens, each with its own exit strategy and its own definition of “forever.”
So what do we do? We own our own domains. We keep local copies. In triplicate. We choose open formats over proprietary ones. We treat every platform as temporary, because it is. We archive not out of paranoia but out of love—love for the things we’ve made, the conversations we’ve had, the small, stubborn act of leaving a mark.
Be gardeners, not just tenants
The web is still the best hope we have for a durable, shared memory. But it requires us to be gardeners, not just tenants. To plant things in soil we control, and to tend them. Because if we don’t, the only record that we were here will be someone else’s ad inventory, and when the ads move on, we’ll move with them—into the quiet, unmarked graveyard of the deleted.
Last week, a MetaFilter member posted a link to what appeared to be a new website for The Dictionary of Obscure Sorrows, John Koenig’s decade-long project to make a “dictionary of made-up words for emotions that we all feel but don’t have the words to express.”
Strangely, it also includes the entire text of the book, from its opening 800-word foreword to a complete archive of all 311 neologisms, with their accompanying definitions, etymology, and short essays, all penned by Koenig.
The book’s original photo-collage illustrations made by Koenig and several other artists are conspicuously missing. Instead, each word has an AI-generated image made with DALL-E 2, riddled with the errors and artifacts typical of that model.
“it’s half-past IŊΨ-o-clock”
A banner at the top of the homepage encourages visitors to “Generate your own words using AI – give your sorrows a voice!” The Submit A Sorrow feature lets you describe a feeling, and then uses OpenAI’s GPT-4 to generate the new word, etymology, and definition, which go into a gallery of “User-Generated Sorrows” with AI generated art.
MetaFilter members were immediately suspicious, and so was I. My wife Ami and I made a card game in 2022, Lost for Words, partly inspired by Koenig’s project. We own a copy of the book, and I’d followed it online for years. The embrace of AI seemed out of character.
If you know any word from the project, it’s probably “sonder,” which spread far beyond its origin, making its way into common parlance and eventually to Dictionary.com and Merriam-Webster.
sonder n. the realization that each random passerby is living a life as vivid and complex as your own—populated with their own ambitions, friends, routines, worries and inherited craziness—an epic story that continues invisibly around you like an anthill sprawling deep underground, with elaborate passageways to thousands of other lives that you’ll never know existed, in which you might appear only once, as an extra sipping coffee in the background, as a blur of traffic passing on the highway, as a lighted window at dusk.
Other words coined by Koenig have found a life outside his project. You may have encountered “anemoia” (a feeling of nostalgia for a time or place you’ve never known), “vellichor” (the strange wistfulness of used bookstores), or maybe “monachopsis” (the subtle but persistent feeling of being out of place).
But “sonder” is the breakaway success. I’d wager most people who have heard the word have no idea it was coined by a guy on Tumblr in 2012.
That success landed Koenig a book deal with Simon & Schuster, and the book became a New York Times bestseller on its release in November 2021.
Two years later, around August 2023, the new Dictionary of Obscure Sorrows website launched, but curiously, with no reference to it from the official Tumblr page or social media.
A Slick Impostor
The mission of Koenig’s project, in his own words, is to “shine a light on the fundamental strangeness of being a human being.”
So it felt strange that he would now be encouraging people to generate new words and definitions with LLMs, a contentious technology that has been trained on so much human writing, but can’t know what it’s like to be human.
I reached out to John Koenig directly to ask if he was involved with the website. He emailed back an hour later:
Yeah man, I had nothing to do with it. Don’t know what to think or do about that, as the site is pretty slick. Nicer than my own, really.
It wasn’t hard to find who was responsible since they list themselves in the “Site Credits” in the footer of every page: Qontour (formerly Prompt Digital), a web design and marketing agency based in San Francisco.
The only hint that the site isn’t authorized is this page in their portfolio, where they talk about how “Qontour built the interactive digital platform – designing the site in Webflow, generating an AI-powered image library, and launching a feature that lets visitors submit their own sorrows and add new definitions to the dictionary.”
On that page, they refer to themselves as “fans” of the book: “The site gives fans (like us) one place to find everything – videos, reviews, interviews, and purchase links – instead of searching across a dozen platforms.”
The problem, of course, is that being a fan doesn’t give them the right to repurpose any of the material for their site.
Copyright and Confusion
In the footer of Qontour’s unauthorized site, they added a copyright notice acknowledging that they don’t own any of the rights to the material on the site, while also licensing all the user-submitted words into the public domain with a CC Zero license.
This betrays a fundamental misunderstanding of how copyright works. Qontour did not have the right to publish the entirety of Koenig’s book to showcase their web design skills.
They also submitted their site to Webflow’s directory to advertise their design business. “This endeavor showcased our expertise in website design, AI-generated content, and extensive content integration.”
Below the button to “Hire Qontour,” a small link to “Copyright Info” misrepresents their work:
The Dictionary of Obscure Sorrows by Qontour is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License. All Rights Reserved. In other words, it’s someone else’s work so you can’t copy it or edit it for any reason, but you can share it with others.
Needless to say, you can’t relicense content you don’t own.
Complicating their claims of it being a fan tribute, Qontour also used their own Amazon affiliate code throughout the site, created under their previous name Prompt Digital, giving them a cut of all book sales.
Those commissions may have been meaningful over the last few years, since the unofficial site is now the top search result for virtually every query related to the book, including the book’s title, the wordscoinedinthebook, and even John Koenig’s name. In every Google search I’ve tried, the unofficial site ranks higher than the official site, the publisher’s site, or Wikipedia.
This is made worse by the rapid shift from traditional web search to conversational AI search, which is easy to manipulate, hides sources, and collapses context into simple answers.
ChatGPT and Gemini both link to the bootleg as the official website, and both claim that John Koenig is the one that created it.
Gemini (left) and ChatGPT (right)
This creates legitimate confusion over its authorship, and arguably, damages the reputation of the project and book with its enthusiastic embrace of AI. The person who originally posted the site to MetaFilter thought it was the official site, and the commenters in the thread then, reasonably, questioned whether the book itself was written by AI.
I asked Koenig if his publisher was planning to issue a cease-and-desist takedown to the site, but didn’t receive a response.
After emailing him, I realized that Simon & Schuster did make moves last year to limit its reach. They filed two DMCA takedowns (1, 2) with Google last July, asking them to remove two pages from the bootleg site from their results. It had no effect.
AI and Consent
It’s one thing for a fan to share or remix copyrighted material out of love for the source material, with no commercial motive. (“No copyright intended!”) It’s another for a marketing agency to take an entire living author’s book, replace its art with AI slop, add an AI word generator, monetize the traffic, promote it in your portfolio, and then outrank the official site everywhere.
This is a more flagrant form of plagiarism than you typically see these days, where human-authored works are laundered with an AI model into something that’s different enough from its sources to avoid legal issues.
But it’s not surprising to see it coming from an agency that has leaned into generative AI so heavily. As they proudly explain, “Every page on this site was written in Claude” using an “author persona” that they call “Q.”
What’s missing here is consent, which feels like the original sin of AI. As I’ve written about manytimesbefore, generative AI models are all trained on a massive corpus of human-authored works without attribution, consent, or compensation, extracting value from creators while centralizing power among a tiny handful of massive tech companies.
On a much smaller scale, Qontour could have reached out to John Koenig for permission to republish his work, collaborating with him on a new, improved website for the book. He might have asked them to limit it to just the words published on his Tumblr, asked for them not to build AI features, or maybe just said no to the whole thing, which would be his right.
The Last Word
What happened to The Dictionary of Obscure Sorrows may have been more brazen, but it isn’t an isolated case.
It’s part of a broad trend happening across the web, where people are using AI to repackage, optimize, and replace the authoritative sources it was trained on for profit.
Nearly every day, I get emailed a newly-launched, obviously-vibecoded website filled with AI-generated content that was designed to siphon attention away from human creators: bloggers, authors, journalists, artists, musicians, and anyone else who slowly, painstakingly makes things for a living. I’m not even sure anymore that the people emailing links to me are human.
The feeling of seeing something you love ingested and repurposed by a machine designed to replace the person who made it seems like a uniquely modern sorrow.
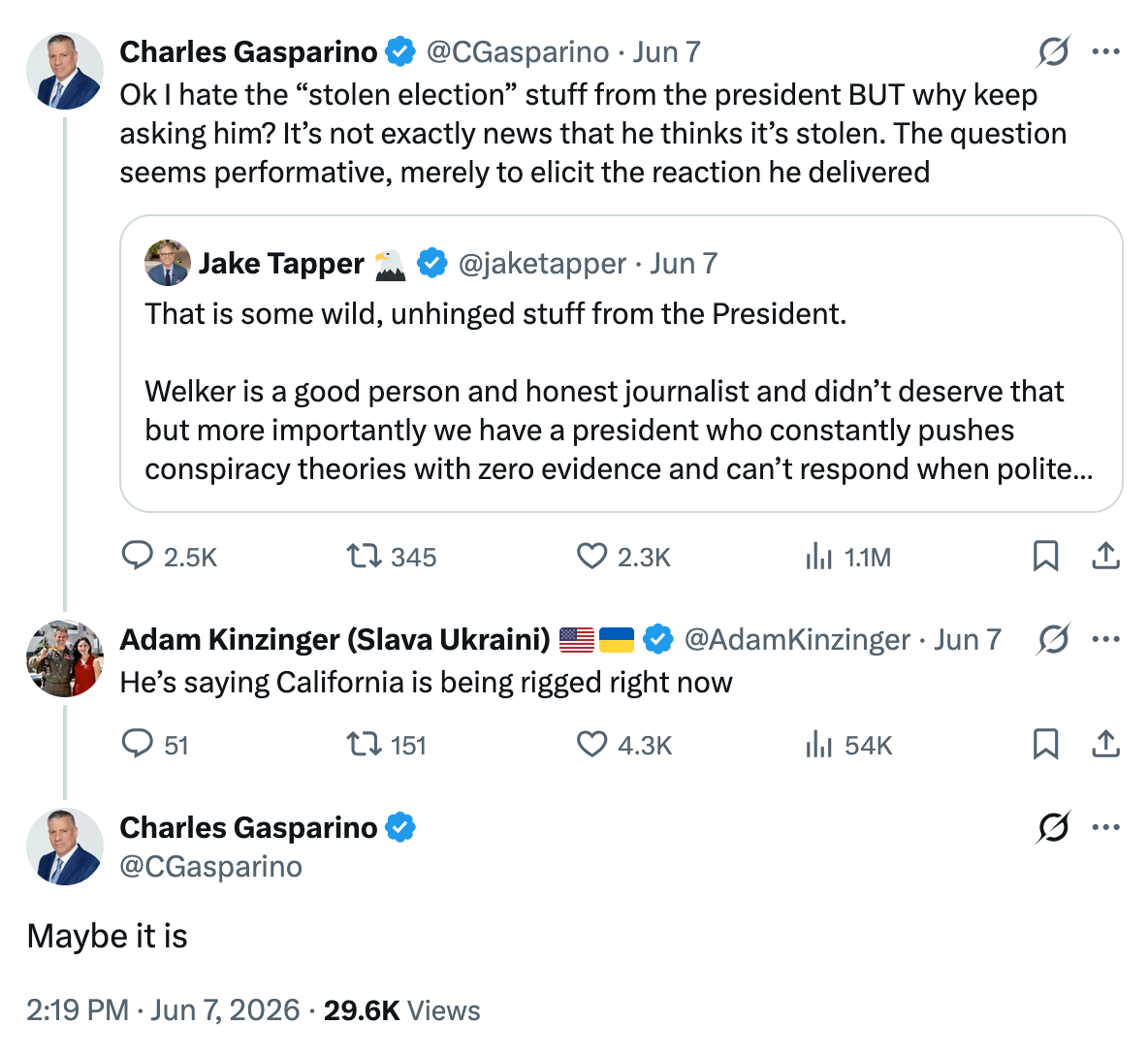
Republicans will never lose another election for the foreseeable future. To be more specific, they will never admit defeat. Largely inspired by the President, election denial has become a tentpole of Republican party politics. Trump himself has never conceded that he fairly lost the 2020 election and 63% of Republican voters agree that it was stolen. Refusal to accept the fair results of unfavorable political outcomes have metastasized throughout Republican politics to the state and local levels. Los Angeles mayoral candidate Spencer Pratt accused his opponent Nithya Raman of “finding votes” as she edged past him while mail-in ballots were being counted. When asked to provide evidence that the election is rigged, Republican Speaker Mike Johnson replied, “these efforts are so diabolical and so far upstream it's impossible to prove. But I think everybody knows instinctively that something is wrong here.” The right-wing Twitter consensus that the LA mayoral race is rigged is so pervasive that it’s infected the minds of Republicans that were previously doubtful of election denial conspiracies.
Charles Gasparino (Fox Business) opining on a recent NBC interview in which the President falsely claimed the LA race was “rigged” before storming off set
Conspiratorial thinking is perhaps the most corrosive force that the Republican Party has unleashed on politics; an addictive cognitive drug that eventually consumes all rational thought. Much like a drug addiction, the more you feed a conspiracy theory the more powerful it gets. Each new data point in the conspiracy reinforces the rest and makes it harder to dislodge. Eventually it grows so large and multifaceted that any new data point can fit somewhere, including falsification of the conspiracy itself.
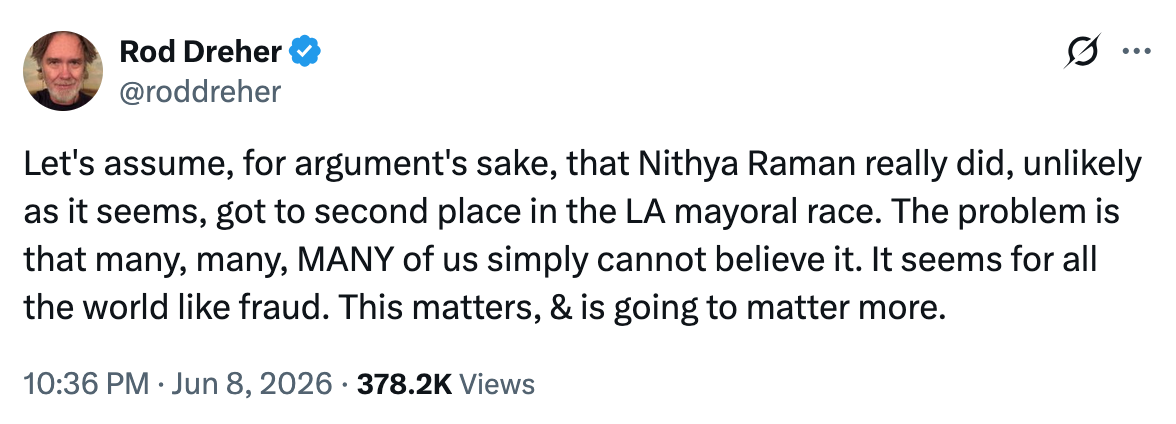
Rod Dreher entertaining the hypothetical possibility that a Democrat got more votes than a Republican in Los Angeles
The digital age has ushered in a sort of golden age for conspiracy theories. Social media provided global platforms for crank theorists whose low-effort high-engagement thinking perfectly aligned with content algorithms. Cross-contamination and political incentives has led to a kind of convergent evolution for what used to be idiosyncratic conspiracists, a “great crank alignment” if you will. Making matters worse, while conspiracies grow more elaborate at political extremes, their style of thinking creeps inwards and takes up a growing share of political discourse. The damage of conspiracism is twofold: time and effort is wasted on combating the conspiracy theory itself and at the same time conspiracy theorists wreak havoc attempting to solve their nonexistent problems. Right now Republicans have a clear advantage when it comes to indulging in conspiracism for political engagement. Yet while I am not one for unilateral disarmament on the Democratic side—especially considering the fact that the Trump administration really is engaging in genuine criminal conspiracies—liberals need to exercise extreme caution before attempting to fight fire with fire.
Trump didn’t start the fire
Democratic voters are by no means immune to lazy or conspiratorial thinking, but the extent to which the Republican party has normalized and amplified conspiracy theories and theorists is without comparison. The Trump-era GOP has brought believers in QAnon, Pizzagate, weather machines, space lasers, chem trails, "9/11 was an inside job," and much more to the highest levels of political office in the country. EPA Administrator Lee Zeldin has stated in official press releases that “Americans have legitimate questions about contrails and geoengineering, and they deserve straight answers.” Robert F. Kennedy Jr. became the Secretary of Health after being personally implicated in worsening a Samoan measles outbreak that killed 83 people by helping to spread anti-vaccine conspiracies. Former Representative Marjorie Taylor Greene claimed that 2018 wildfires in California could have been caused by a solar-powered laser beam from space—controlled by, of course, the Rothschilds. The President himself is the architect of an election denial campaign that resulted in an insurrection at the Capitol that successfully delayed the certification of a Presidential election for the first time in American history.
This tendency for conspiracization did not begin in 2016; it’s been a facet of mainstream Republican politics for as long as I’ve been alive. Right-wing media outlets indulged and enabled racist speculation regarding President Obama’s birthplace and religious beliefs for years—including from future President Trump. These speculations were so widespread and long-lasting that they played a role in both of President Obama’s election campaigns. During a 2008 town hall an audience member raised concerns that then-Senator Obama was “an Arab” and John McCain had to speak over a booing crowd to reassure them that “Obama is a decent person.” Four years later Mitt Romney indulged these racist speculations when he told a rally crowd, “no one’s ever asked to see my birth certificate … They know that this is the place that we were born and raised.”
The difference between McCain rejecting his voters’ conspiracism and Romney later indulging it serves as an omen for how Republican politicians would not just abandon their role as gatekeepers but actively encourage conspiracism in the American public. In 2015, the US military engaged in a training exercise named “Jade Helm 15” in the southern United States designed for practice among civilian populations. Right-wing conspiracy theorists ran wild, convinced that the exercise was a cover story for the imminent onset of martial law. Alex Jones speculated that “Helm” stood for Homeland Eradication of Local Militants. Elected Republicans’ response was not to calm the public and dismiss these insane theories: instead, Governor Abbott mobilized the Texas State Guard to “monitor” the exercise. Ron Paul applauded Abbott for “sympathizing with people who have great concerns with federal takeovers.”
One could argue that the Bush administration’s campaign to justify the Iraq War was in essence a conspiracy theory created and propagated by the federal government. In 2006, Jonathan Stein and Tim Dickinson published a timeline for how the United States ended up invading Iraq that documents much of the evidence cited by the White House, its flaws, and how administration officials played fast and loose with the facts, warping them into whatever suited their narrative. The desperate search for justification to depose Saddam Hussein used the same conclusion-first thinking that defines conspiracism.
It was all about finding a way to do it. The president saying, ‘Go find me a way to do this.'
—Treasury Secretary Paul O’Neill, recalling Bush’s first national security meeting
On September 12th, 2001, Richard Clarke (then National Coordinator for Security, Infrastructure Protection, and Counter-terrorism) remembered, “[Bush] told us, ‘I want you, as soon as you can, to go back over everything, everything. See if Saddam did this.'” According to Clarke, Bush asked for “any shred” of evidence Saddam was involved. On September 21st the intelligence community informed Bush there was no evidence linking Saddam to the 9/11 attacks. The next month Secretary of Defense Donald Rumsfeld formed his own intelligence group to search for evidence linking Saddam to terrorism.
US scrambling to establish a link between Iraq and Al Qaida is so far frankly unconvincing … It sounds like a grudge between Bush and Saddam.
There has been no credible evidence to link Iraq with Al Qaida.
—Downing Street memos (March 2002)
You can’t distinguish between Al Qaeda and Saddam when you talk about the war on terror.
—President Bush (September 2002)
In April 2001, months before the 9/11 attacks, a CIA analyst told the Bush administration that Iraq had purchased a large number of aluminum tubes that could only be used for nuclear centrifuges. In August the Energy Department (the agency tasked with American nuclear energy and weapons) rejected this theory in a memo to the CIA. In March 2002 Ambassador Joseph Wilson informed the CIA that based on his investigation there is no indication that Iraq is buying yellowcake uranium. French officials concurred in typical French fashion: “We told the Americans, ‘Bullshit. It doesn’t make any sense.'”
Almost exactly one year after 9/11 the New York Times ran a front-page story citing a White House official claiming Iraq had purchased aluminum tubes specifically for enriching uranium. That same day President Bush cited a non-existent IAEA report that Iraq was six months from developing a nuclear weapon, National Security Advisor Condoleezza Rice repeated the aluminum tube theory on CNN, and Vice President Dick Cheney lied on NBC, stating, “we do know, with absolute certainty, that he is using his procurement system to acquire the equipment he needs in order to enrich uranium to build a nuclear weapon.”
What strikes me about this timeline is how much it resembles President Trump’s election denial conspiracy theory, two decades later. One of the most damning excerpts from the January 6th Select Committee report is a series of instances in which Trump repeats claims that his own administration has previously told him are false, much like the aluminum tube theory being rejected by the Energy Department only to resurface a year later as “absolute certainty.”
“And so he said, ‘Well, what about this? I saw it on the videotape, somebody delivering a suitcase of ballots.’ And we said, ‘It wasn’t a suitcase. It was a bin. That’s what they use when they’re counting ballots. It’s benign.’”
—Then-Deputy Attorney General Jeffrey Rosen (December 15, 2020)
“There is even security camera footage from Georgia that shows officials telling poll watchers to leave the room before pulling suitcases of ballots out from under the tables and continuing to count for hours.”
—Donald Trump (December 22, 2020)
“I told the President myself that several
times, in several conversations, that
these allegations about ballots being
smuggled in in a suitcase and run
through the machine several times, it
was not true, that we looked at it, we
looked at the video, we interviewed the
witnesses, that it was not true . . . . I
believe it was in the phone call on
December 27th. It was also in a meeting
in the Oval Office on December 31st.”
—Acting Deputy Attorney General Richard Donoghue (December 27 & 31, 2020)
“[S]he stuffed the machine. She stuffed the ballot. Each ballot went three times, they were showing: Here’s ballot number one. Here it is a second time, third time, next ballot.”
—Donald Trump (January 2, 2020)
“Then he raised the ‘big vote dump,’ as he called it, in Detroit. And, you know, he said, people saw boxes coming into the counting station at all hours of the morning and so forth … I said, ‘Mr. President, there are 630 precincts in Detroit, and unlike elsewhere in the State, they centralize the counting process, so they’re not counted in each precinct, they’re moved to counting stations, and so the normal process would involve boxes coming in at all different hours.’ … I mean, there’s no indication of fraud in Detroit.’”
—Attorney General William Barr (December 1, 2020)
“I’ll tell you what’s wrong, voter fraud. Here’s an example. This is Michigan. At 6:31 in the morning, a vote dump of 149,772 votes came in unexpectedly. We were winning by a lot. That batch was received in horror … In Detroit everybody saw the tremendous conflict … there were more votes than there were voters.”
—Donald Trump (December 2, 2020)
Conspiracy theories and the lies they rely on are an addiction. When your conclusion is set in stone and you treat evidence as a tool to get there, each lie begets another. Reality is internally consistent, so to appear truthful a conspiracy theorist must continue to repeat the same lies over and over again. Donald Trump is without a doubt the biggest liar to ever sit in the Oval Office, but Republicans have been practicing for decades.
No reliable information on whether Iraq is producing and stockpiling chemical weapons.
The Iraqi regime possesses biological and chemical weapons, is rebuilding the facilities to make more, and, according to the British government, could launch a biological or chemical attack in as little as 45 minutes after the order is given.
—President Bush (September 28, 2002)
While a small number of old, abandoned chemical munitions have been discovered, ISG judges that Iraq unilaterally destroyed its undeclared chemical weapons stockpile in 1991. There are no credible indications that Baghdad resumed production of chemical munitions thereafter.
—Charles Duelfer, Comprehensive Report of the Special Advisor to the DCI on Iraq’s WMD (April 25, 2005)
Brainworms are contagious
Even with the Republican Party’s many years of practice, conspiracism is not a uniquely right-wing phenomenon. Left-flavored populism has the same tendency towards oversimplified narratives and scapegoating a vague, shadowy elite. Right-wing crazies think the source of all evil is globalists, “the Cathedral,” or the Jews while left-wing crazies think it’s billionaires, “Wall Street,” or Israel. The conspiratorial mindset takes the fact that there are evil billionaires (see: Elon Musk) or evil Jews (see: Jeffrey Epstein) and extrapolates it in both directions, attributing every problem to an abstracted concept of the villain. This two-step is what makes conspiracism so corrosive to public discourse. It hijacks good-faith actors discussing genuine problems as vessels to spread a bad-faith worldview that inherently cannot solve real problems.
The most relevant and timely example of left-wing conspiracism can be found in the simultaneous rise in anti-Israel and antisemitic sentiment since the October 7th attacks and subsequent ethnic cleansing in Gaza. Opposition to Israel bleeding into antisemitism is not a new phenomenon on the far left—the initial reaction for some to October 7th speaks for itself—but as the opposition to Israel grows, so too does antisemitism in proportion. The double-edged sword of conspiracism is found in both the direct harms of antisemitism as well as in poisoning the well for otherwise legitimate criticism of Israel.
A focal point for rising anti-Israel sentiment within Democratic politics has been heightened scrutiny and criticism of AIPAC (the American Israel Public Affairs Committee) and the candidates who accept their support. Disliking AIPAC and the causes they stand for is not inherently conspiratorial or antisemitic. A voter who opposes the actions of the Israeli government has every reason to oppose a political advocacy group that supports the actions of the Israeli government. The problem is when “AIPAC” stops referring to the actual real-world AIPAC and instead refers to an imaginary version made to play the role of a conspiratorial villain. Take, for instance, the group “Track AIPAC” whose infographics have become instantly recognizable on social media. The account purports itself to track how much money political candidates have accepted from AIPAC, dressing the number up in a scary red or bright green background depending on the result. There’s just one small issue: Track AIPAC doesn’t actually track AIPAC.
This Track AIPAC graphic from yesteryear claims that Georgia Senator Raphael Warnock received $928,350 from the “pro-Israel lobby.” But according to FEC data, Senator Warnock received no such donations from AIPAC. He’s not even listed on AIPAC’s website as an endorsed candidate. What Track AIPAC actually tracks appears to be contributions from any Israel-related group (such as the much less militantly pro-Israel J Street) as well as any individual donors who have themselves donated to Israel-related groups (see Christopher Webb for more). After people criticized Track AIPAC for the misleading information, they “updated” their graphics to supposedly show more detail. It’s not much of an improvement, simply splitting the total into two similarly opaque “PAC” and “Individual” categories.
Such an obfuscated and dishonest methodology lends itself to worse impulses than just exaggerated numbers. Take the case of Senator Chris Van Hollen and House candidate Daniel Biss, neither of whom have taken AIPAC contributions. Van Hollen got the green background and $0.00 while Biss got a red background and $460,357. This is bizarre considering Biss is a vocal critic of AIPAC and according to him the organization spent millions on his opponent. So why does he get the harsh treatment compared to Van Hollen? Maybe it’s the fact that Daniel Biss is Jewish.
Track AIPAC is mostly an online phenomenon—the graphics are designed to be used on social media for quote-dunks and ratios—but its conspiratorial style of politics has unfortunately found purchase in more professional spaces. Mehdi Hasan, formerly of MSNBC, hosted the pair behind Track AIPAC (Cory Archibald and Casey Kennedy) for an interview with his own media company Zeteo. The interview is titled “Meet AIPAC’s Nightmare” and is far from the hostile interrogations that Mehdi Hasan is well known for. In the blurb attached to their interview, Hasan describes the two as “the brains and brawn behind the effort to bring transparency back to US elections” and says that the project “names and shames US politicians on AIPAC’s payroll.” This could be a careless oversight, but considering Zeteo just recently published a very questionable article on the USS Liberty incident (a long-standing conspiracy theory that Israel intentionally attacked a US vessel) I don’t think they should get the benefit of the doubt.
Educational polarization provides some protection against conspiracism—it’s harder to do well in school if you believe in chemtrails and a flat earth—but sometimes it just means the conspiracy theories need to sound a little bit more believable. Opposition to the AI-driven data center construction spree has rapidly grown among Democratic voters, including support for an outright ban on new projects. Many arguments against data centers (or AI more broadly) are based on false claims regarding heat output or water usage. Up north in the current hotseat for left-wing slopulism—Graham Platner’s state of Maine—nearly half of Democratic voters think Kamala Harris was the legitimate winner of the 2024 election according to a May poll. The fact that election denial has essentially zero purchase among elected Democrats merely speaks to how much better Democratic politicians are at gatekeeping this side of the aisle’s latent conspiracism.
There is a certain Bluesky post that has entered the personal lexicon of me and many other terminally online liberals. I speak, of course, of Glonzo.
The original post was made in the midst of a social media driven panic regarding drone sightings in New Jersey, but now “Glonzo” serves as shorthand for falsehoods that have widespread public belief. Thinking AI is using up all the water is Glonzo. Thinking immigrants are stealing all the good jobs is Glonzo. Thinking we can easily save trillions of dollars by cutting “waste, fraud, and abuse” from the federal budget is Glonzo. Donald Trump’s victory in 2024 on a campaign constructed entirely out of Glonzo issues (e.g. mass deportations will solve the housing crisis) left many liberals reeling. Some decided in the wake of this success to harness Glonzo for good. If the public is going to be stupid then at least point their stupidity at the bad guys. Perhaps the biggest example of this is the ongoing Epstein saga, though this is somewhat of a special case in that it has a genuine kernel of truth at its core (more on this later).
Populism and conspiracism are not quite synonymous but they are inextricably linked. The essence of populist rhetoric is positioning you, the common man, against a nefarious and powerful elite that is to blame for your problems. It’s not hard to see how one leads to the other. Populism is not a foreign language to the left—anybody with an interest in politics can easily imagine Bernie Sanders reciting his trademark “the one-percent” stump speech—but a rising tide raises all ships and Donald Trump remaking the GOP in his MAGA image has spurred the rise of new populists on the left and motivated some established politicians to lean in.
My caution to those eager to embrace the dark side is a reminder that lying is addictive and effective governance requires an accurate view of the world. Donald Trump’s presidency is awful not just because it has turned the most powerful nation in history into a vehicle for pointless cruelty. It also fails on its own merits because they’ve drunk too much Kool-Aid. MAGA genuinely thought turbocharged tariffs would lead to a resurgence in American manufacturing when basic economics would have told them it would do the opposite. They really did believe the only failure of America’s previous Middle Eastern wars was woke liberals not blowing the bad guys up hard enough. What happens if you run a political campaign promising to hunt down Glonzo to lower people’s power bills and win? Everyone’s power bills will stay the same and in four years you’re gonna lose to the guy who accuses you of being on GPAC’s payroll. What sets good leaders apart from bad is the ability to appeal to voters’ impulses on the campaign trail without succumbing to them while in office. To see the difference between riding the populist wave and getting dragged under, look no further than someone living long enough to see themselves become the villain.
Ned Resnikoff, author of the upcoming Build or Die, wrote a great piece on Senator Elizabeth Warren and her recent downfall as the resident progressive policy wonk in Congress. I’m not exactly in the same boat as Ned—he recalls being in the audience for a conference speech by Warren in 2015 that I didn’t attend because I was too busy playing Destiny: The Taken King after school—but I resonate a lot with how he held Senator Warren in high regard for her attention to policy details. As he notes, an unofficial campaign slogan for her 2020 Presidential run was “I have a plan for that.” It is this reputation as a “bona fide serious person” that makes the Massachusetts Senator’s recent missteps that much more disappointing.
The first sign of trouble for me was when she endorsed a plan President Trump floated about capping credit card interest rates, going so far as to publish a Fox News opinion piece criticizing Trump when the plan never materialized. Then came the ROAD to Housing Act, a legislative package co-sponsored by Senator Warren ostensibly designed to ease the nation’s housing shortage. Buried within the bill was a provision that reeked of slopulism: banning individuals or firms from owning more than 350 single-family houses. A popular Glonzo issue is the idea that a significant driver of high housing costs is large Wall Street investment firms (e.g. BlackRock, though technically it’s a different firm named Blackstone that invests in housing) buying up a large number of houses to speculate on their value. In reality, big investors own a tiny fraction of housing stock—0.59% according to this analysis—and the houses that they do own are mostly used as rental properties, not sitting vacant. While it’s true that Wall Street investors do not own any meaningful share of existing housing stock, the language of this bill essentially outlaws large firms from building new rental housing at scale. Thus a pointless regulation targeting 0.59% of the housing market could cripple a much larger share of new housing construction. According to estimates by real-estate firms, the build-to-rent sector built as many as 70,000 to 130,000 new homes in 2024. Senator Warren not only co-sponsored the bill but specifically supported this provision. Her argument for such can be found on the Senate Banking, Housing, and Urban Affairs Committee website:
Allowing private equity firms and other large institutional investors to snatch up thousands of homes can make it impossible for individuals and families to buy their own home … This is extremely popular with the American people: 64% of Americans support reining in corporate landlords and institutional investors to lower housing costs and 73% support banning corporate investors from single-family homes … Institutional investors have the resources to outbid families and have taken hundreds or thousands of single-family homes off the market.
This is pure, uncut, black-tar slopulism injected straight into the vein. Investors owning less than one percent of housing is not the reason why any American families struggle to afford a home. Rental houses are not “off the market.” Imagine the absurdity of demanding a ban on owning more than 350 cars and thus destroying the rental car industry because they’re “taking vehicles off the road that American families deserve to drive.” It’s total nonsense. Indulging this kind of rhetoric on the campaign trail is one thing, but implementing it as actual legislative policy is malpractice. Nobody benefits from this. Homeownership will not magically increase just because we’ve outlawed the rental market. In reality many large firms will simply stop building new rental homes and everyone will be left worse off. In perhaps the biggest irony, there is economic research showing that investors buying into the single-family housing rental market can serve to decrease racial segregation and socioeconomic inequality by lowering the barrier of entry into rich neighborhoods—results that would normally be progressive policy goals. So much for the progressive policy wonk.
Indulging in slopulism also makes it easier for worse figures to rise. Elizabeth Warren was one of the first national Democrats to endorse Graham Platner in his primary campaign, describing him as “the real deal” and “a fighter [who’s] ready to take that fight to Washington.” Platner—who bears a slight resemblance to Bane in his Kik profile picture—has not merely adopted the slopulism but was born in it, molded by it. Even if it weren’t for his taste in 1940s German tattoo art or concerning history with women, the man’s politics are completely without substance. Every tweet I’ve read, speech I’ve heard, every commercial I’ve seen is just anti-establishment angst pointed in no clear direction with no clear purpose and no clear goals. Sure I would rather him sit in Congress than Susan Collins, but his brand of politics is not one that should be encouraged or amplified.
The future of Democraticpolitics should ideally include fewer candidates who run TV ads that open with “some of the most powerful Democrats and Republicans in the country were on Epstein Island … it seems the only thing the party establishments can agree on is a love of Jeffrey Epstein.”
The boy who cried wolf was right
Yet the problem with trying to avoid conspiratorial thinking in the Trump era is the fact that he has made many conspiracy theories come true. The President, his Cabinet, military officers, and many members of Congress are, strictly speaking, engaging in dozens of criminal conspiracies. Donald Trump and his cronies have discovered a clever loophole where if you do enough crimes in public then a lot of people stop perceiving them as crimes (including the Supreme Court of the United States). It’s a bizarro-world inversion of the cover-up being worse than the crime, an adage coined to describe the Watergate scandal. Turns out if Nixon just went on TV and said, “yeah I paid some guys to break into the hotel to spy on those crooked Democrats, what of it?” nobody would have cared.
When I see polling results among Democratic voters showing that shockingly high numbers of people believe the assassination attempts on Trump were staged or that Kamala Harris really won the 2024 election, part of me wonders if I can really blame them. When you consider the objectively true list of things that Donald Trump has done in the past, is doing right now, or has openly bragged about wanting to do in the future, is it really that much of a stretch? Off the top of my head I can name at least a half-dozen stories that would sound schizophrenic if they weren’t our current reality.
The United States government has killed hundreds of people by drone striking random boats off the coast of South America with zero pretense of due process
The President sued the IRS for ten billion dollars and planned to order them to forfeit the case
Massive multi-million dollar bets are routinely being made moments before major political decisions are publicly announced
The President is selling pardons to wealthy criminals for millions of dollars
The Department of Justice is pursuing the President’s political and personal enemies, including his rape victim, with criminal investigations
Worst of all, the most damaging conspiracy theory in modern American history is actually true. There really was an attempt to illegally change the results of the 2020 election. It was carried out by Donald Trump.
Following his loss on election night, the President of the United States pressured state officials to change their results, filed over sixty lawsuits across the country seeking to obstruct or overturn vote counts, coordinated across seven states (Arizona, Georgia, Michigan, Nevada, New Mexico, Pennsylvania, and Wisconsin) to submit fraudulent Electoral College votes to Congress, organized a mob of thousands and ordered them to march on the Capitol building, then as the violent mob broke into the Capitol building attempted to coerce lawmakers and the Vice President into accepting his fraudulent votes. All of this is objective fact, meticulously documented in a public Congressional report. It’s not beyond belief that Trump might have tried to rig the 2024 election—or for that matter that he might try to rig 2026 or 2028—because he already tried once before.
And so I feel trapped in this three-pronged dilemma. On one hand I understand that I am not the typical voter. If any politician ran a campaign that perfectly appealed to me in style and substance they would probably end up with negative votes. On the other hand leaning into populism or conspiracism is playing with fire and runs the risk of sabotaging one’s ability to govern. Then on the other-other hand it’s literally true that there are evil billionaires (and now one trillionaire) manipulating the government to enrich themselves and commit heinous crimes.
Ryan Geddie has a pair of video essays that heightened a lot of this tension for me. The first (Ezra Klein and What Happened to American Liberals?) addresses many of my problems with the current liberal pundit class: the liberal consensus established in the wake of the Cold War was taken for granted and too many forgot how to fight for liberalism against illiberal opponents, sometimes living in denial that illiberal opponents even exist. The second (Liberal Populism is The Future of the Democratic Party) gave me a kneejerk reaction from the title alone. This was my vision of the bad ending: the future of American politics descending into fascism versus slopulism. Swallowing my pride and watching more, Geddie points out some things I’m missing that maybe, just maybe, could point to a better way forwards.
The opening line, “for a certain kind of liberal the worst thing you can be in the whole world is a populist” is spot-on, almost like he was spying over my shoulder while I was writing this. He goes on to argue that because populism is not itself a political ideology but a style of political rhetoric, there is no inherent reason why liberalism must exist in separation or opposition from populism. This stands opposed to the framework of many prominent liberals today, such as Derek Thompson, who is quoted in the video remarking, “I am not a populist, I am a liberal” (which admittedly sounds a lot like something I would say). But Geddie points to several historical liberal figures—some of whom defined liberalism for their generations—who made populist appeals in service of their liberal ideology. Thomas Paine wrote in Common Sense “of more worth is one honest man to society than all the crowned ruffians who ever lived.” A century and a half later FDR both sold his New Deal agenda with populist rhetoric and successfully led the country through its greatest crisis since the Civil War. It cannot be the case that populism is inherently incompatible with liberal government. Maybe the problem isn’t that populism is illiberal. Maybe the problem is that we forgot how to make liberalism popular.
Later in the video Geddie plays another clip of Derek Thompson where he dismisses the need for liberals to put forth a political narrative: “stories are for children,” he jokes. I find myself stuck in cognitive dissonance. Thompson is arguing against something I despise, populism, with an argument that encapsulates the fatal flaw of modern liberalism. You cannot, as Thompson puts it, “just have a plan to make people’s lives better” when the debate is over what makes a life better. This is what debate nerds like me refer to as begging the question. A detailed policy plan to provide more efficient government services has nothing to offer against opponents who reject the idea that the government should serve the people. Our political battles right now are not over the best ways to spend government money, but whether a President should withhold government money from states that don’t vote for him. When Stephen Miller claims that immigrants are a drain on the economy it does not matter that he is incorrect. Stephen Miller doesn’t care about the economy, he cares about lowering the number of non-white Americans by any means necessary. Whatever comes after this administration cannot be limited to a bullet-pointed list of policy ideas, regardless of how good those ideas are. The debate is not about what government should do, a question perhaps answered by something like “Project 2029”; it is a debate about what government should be, a question answered by something more like the Reconstruction Papers. It’s for this reason I was drawn to Liberal Currents and motivated to write here. They understand the stakes.
If it is indeed the case that successful liberal populism can exist, then where is it? Geddie puts forth the not-yet-official but almost certain-to-be Presidential candidate Jon Ossoff as an example. As the first national politician I’m aware of to use the term “Epstein class,” the Senator from Georgia is definitely engaging in populism, so much so that my spider-senses start tingling. Is the term “Epstein class” inherently antisemitic? Doubtful coming from a Jewish Senator, but almost certainly coming from others. Is it inherently conspiratorial? Yes, but then again Jeffrey Epstein genuinely did orchestrate a criminal conspiracy and he really was friends with a lot of powerful people. Obviously Ossoff does not set off the same red flags that someone like Platner does when he references “corrupt elites,” but even a seasoned veteran like Elizabeth Warren fell victim to a wild Glonzo chase. Geddie acknowledges Ossoff’s strong populist bent, even playing a clip of the aforementioned “Epstein class” line, but argues that it is paired with a strong sense of liberal principles evidenced by a later segment from that same speech:
I listened to a speech a few months back by a Senator from Missouri who’s aligned with the President. What I think I heard him say was that the only real Americans are those descended from the original European settlers. Now maybe he forgot the Mayflower itself was full of religious exiles fleeing persecution, but our heritage isn’t limited to that of the pilgrims and those who settled the West. America’s heritage includes descendants of slaves who won liberation from slavery and Jim Crow. It includes the Creek Indians who lived in middle Georgia for eleven centuries straight. It includes immigrants from every region and continent who arrived here fleeing persecution or seeking opportunity. Americans are not a race. We’re a people … That is what makes us exceptional.
This is the strongest and most direct refutation I have seen of the “heritage American” narrative from a politician on the national stage. It is not an argument for immigration on its merits as policy but for its own sake as something essentially American. That is the real debate that American liberals need to be capable of fighting and winning, not how to best achieve “abundance” or “affordability” or whatever new buzzword surfaces by 2028. My concern is whether or not people see much of a difference between someone like Ossoff and someone like Platner if they're both giving speeches about the corrupt Epstein class. The next Democratic administration already has an immense amount of work cut out for them. They cannot afford to waste any time or effort chasing after Glonzo.
Populist rhetoric and the conspiracism it breeds is dangerous; Democrats should look before they embrace the public’s latest bugbear. Indulging exaggerated narratives and false beliefs on the campaign trail can spell self-sabotage when the time comes to make actual policy. At the same time there are very real conspiracies afoot that cannot be defeated with merely a good enough tax code or the right set of regulations. There can be no return to normalcy unless a lot of rich and powerful people spend the rest of their lives in federal prison. Elections cannot be won on policy platforms and think tank papers. Liberals need to foster and embrace a popular vision of what it means to be American, what America should look like, and what the purpose of a government even is in the first place. Not only is this needed to win the public’s faith in 2028, it is a necessary compass for the new government to follow in its reconstruction. I just don't think screaming “Epstein class” is the way to get there.
Explanation:
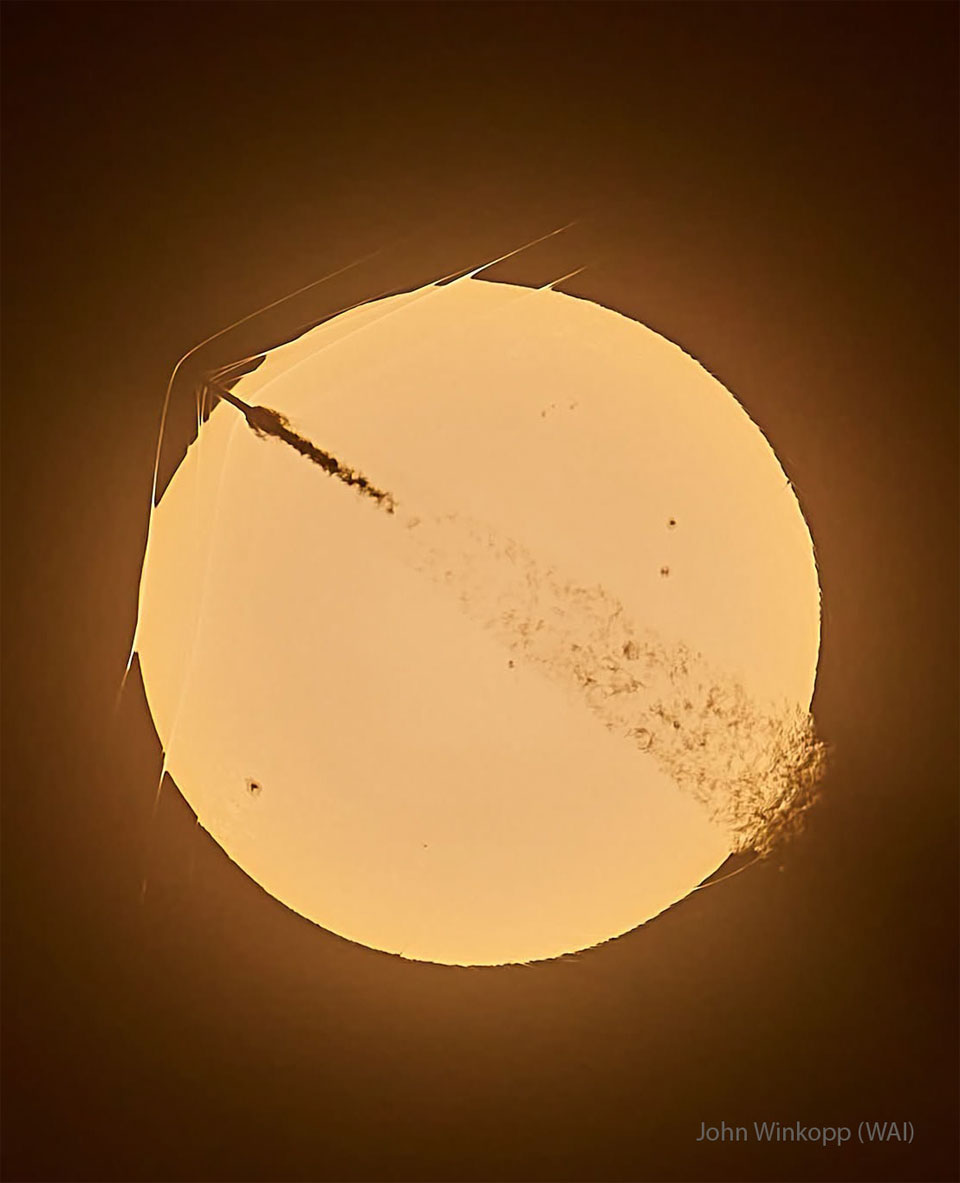
What's happening to this Sun-crossing rocket?
The SpaceX
Falcon 9 rocket, visible on the upper left,
launched only about one minute before this amazing image was captured.
As it rose to low Earth orbit from
Cape Canaveral,
Florida,
USA,
in late May, the rocket became
supersonic before it
crossed the disk of the distant Sun --
from the perspective of the well-placed photographer.
The spacecraft's high speed caused
bow-shaped compressed-air
shockwaves to form across leading surfaces,
with at least three visible even outside
the Sun's disk because they
refract sunlight.
The
trailing exhaust caused
turbulence visible on the lower right.
None of this was damaging to the robotic
Starlink 10-53 mission,
which delivered 29 communications satellites to
low Earth orbit as planned.
And if that isn't
amazing enough - the Sun had
spots!

















{kind=link}
{kind=link}